입출력 시스템과 디스크 관리
by
Songhee Lee
들어가기 전에
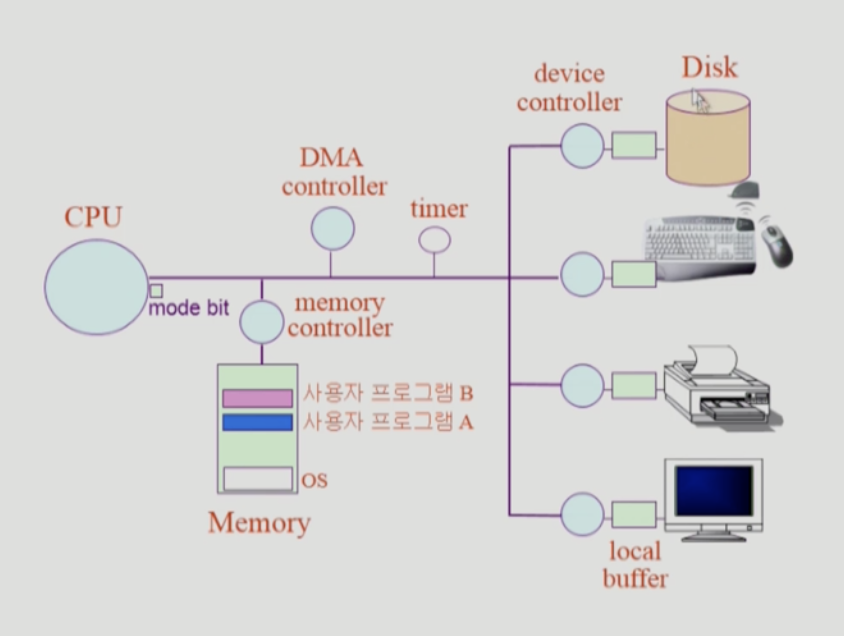
- 각각의 I/O Device는 CPU가 아닌 각각의
Device Controller가 관리한다. -
그리고 Device controller 를 위한 작은 메모리 공간을
local buffer라고 부른다. (일종의 register) -
입출력이 필요한 경우
- 사용자 프로그램은 시스템 콜을 통해 운영체제에 I/O 요청
- trap 사용해 인터럽트 벡터의 특정 위치로 이동 -> 서비스 루틴으로 이동
-
운영체제는 Device controller 에게 요청
- 입출력이 끝나면 Device controller 가 interrupt 를 걸어 대답한다.
여기서 잠깐!
Device driver : 각 장치별 처리 루틴 (소프트웨어)
Device Controller : 각 장치를 제어하는 일종의 작은 CPU (하드웨어)
입출력 시스템
컴퓨터는 필수 장치(CPU, 메모리)와 주변장치(입출력장치, 저장장치)로 구성되고,
주변장치는 데이터 전송 속도에 따라 저속 주변장치와 고속 주변장치로 구분된다.
-
저속 주변장치: 메모리와 주변장치 사에이 오고 가는 데이터 양이 적어 데이터 전송률이 낮은 장치.
ex) 키보드, 마우스, 스캐너
-
고속 주변장치: 메모리와 주변장치 사에이 오고 가는 데이터 양이 많아 데이터 전송률이 높은 장치.
ex) 그래픽 카드(초당 수집장의 그래픽을 보여주어야 함)
각 장치는 메인 보드에 있는 버스로 연결되고, 버스는 여러 개의 버스를 묶어서 사용하는데 그 통로를 채널이라고 한다.
여러 채널을 효율적으로 사용하기 위해 전송 속도가 비슷한 장치끼리 묶어서 채널을 할당한다.
입출력 버스의 구조
폴링 방식(초기 구조)
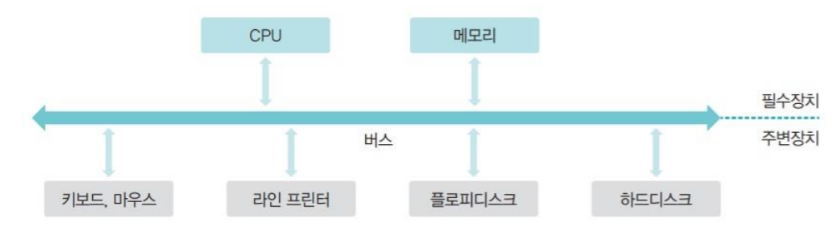
초기에는 모든 장치가 하나의 버스로 연결되고, CPU가 작업을 진행하다가 입출력 명령을 만나면 직접 입출력 장치에서 데이터를 가져왔는데 이를 폴링(polling) 방식이라고 한다.
-
폴링 방식: 하드웨어 상태를 수시로 체크하여 명령을 받을 수 있는지 확인
-
단점 : 주변 장치는 CPU와 메모리보다 매우 느리기 때문에 폴링 방식을 사용하면 CPU 대기 시간이 길어져 작업의 속도가 매우 느려진다.
입출력 제어기를 사용한 구조 (Device Controller)
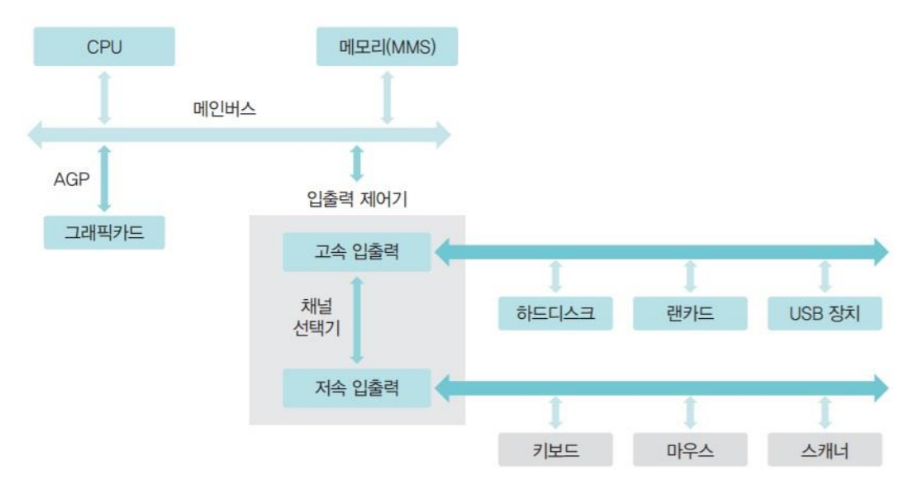
모든 입출력을 입출력 제어기(I/O Controller)에 맡기는 구조
- 입출력 제어기는 2개의 채널로 나뉜다.
- 메인버스는 고속으로 작동하는 CPU와 메모리를,
- 입출력 버스는 주변장치가 사용한다.
입출력 처리 방식 (빠른 순서순)
채널에 의한 I/O
- DMA 개념을 확장해 구현한 입출력만을 위한 전용 처리 장치
- CPU처럼 독자적으로 메모리에 저장된 명령어를 처리할 수 있다.
- 입출력 채널은 CPU 개입 없이 입출력 처리를 수행하며,
- 선택 채널 (selector channel) : 한 번에 하나의 입출력 장치 제어
- 다중화 채널 (Multiplexor channel) : 한 번에 여러 장치에 대한 입출력 제어
버퍼링
-
버퍼 : 데이터를 임시로 저장하거나 보유하는 데 사용되는 영역 (메모리)
-
속도가 다른 두 장치의 속도 차이를 완화하는 역할을 한다.
입출력 장치는 느린 장치를 통해 들어오는 데이터를 버퍼에 모아 한꺼번에 이동시켜 느린 속도를 보완한다.
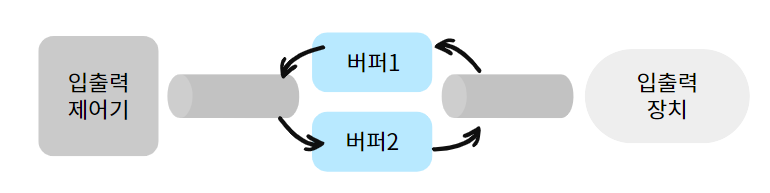
-
이 때 한 버퍼는 데이터를 담는 용도로 쓰고, 다른 버퍼는 데이터를 가져가는 용도로 쓴다.
- 시스템 효율성을 위해 운영체제에서는 버퍼가 가득 찼을 때 입출력장치로 데이터를 전송하도록 설계되어 있다.
- 이러한 특성 때문에 외부 저장 장치를 제거하거나 파일 입출력 시 버퍼에만 있고 저장장치에는 반영되지 않는 경우가 생길 수 있다.
스풀링 (Spooling)
- 메모리가 아닌 디스크를 버퍼로 사용
- 대부분의 프린터 등의 입출력 장치들은 스풀링 기능을 적용
직접 메모리 접근 (DMA)에 의한 I/O
-
Direct Memory Access
-
일반적으로 메모리는 CPU에서만 접근이 가능한데, CPU에서 직접 메모리를 access 하면 속도가 느리다는 단점이 있다.
-
직접 메모리 접근(DMA)은 CPU를 대신해 I/O 장치와 메모리 사이의 데이터 전송을 담당하는 장치를 지칭하고,
-
입출력을 위한 인터럽트 발생 횟수를 최소화해 컴퓨터 시스템의 효율을 높이는 방식이다.
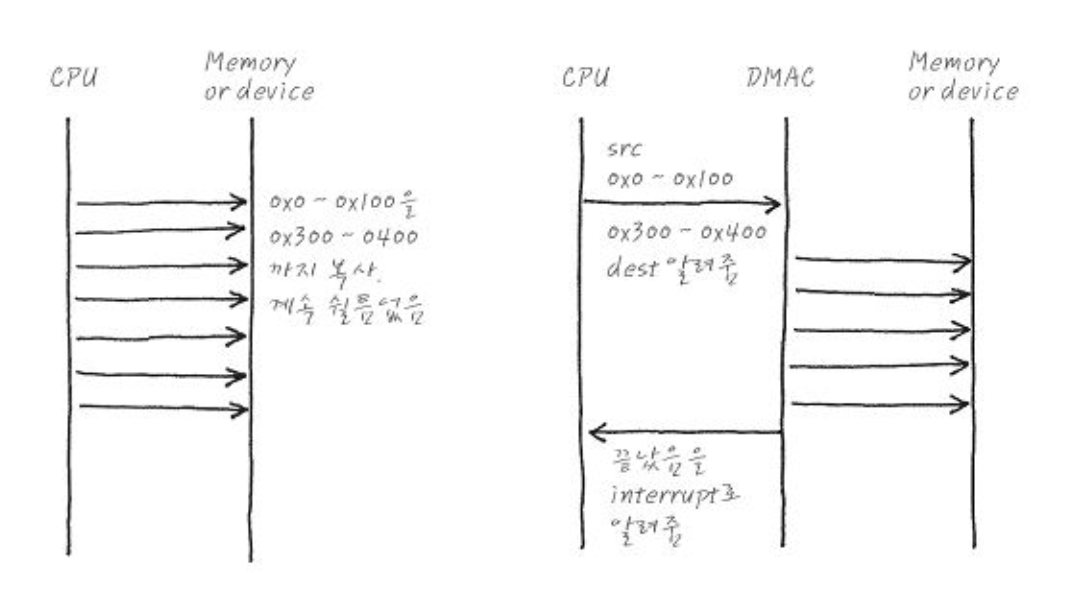
- CPU는 자기 할 일 하고 있다가, DMA가 적절히 조율해서 CPU 한테 한 번만 interrupt 건다.
[ 실행 순서 ]
-
CPU->DMA: 프로그램에서 I/O 발생디스크 컨트롤러에게 데이터 읽어오고 checksum 확인하라는 명령 발동.
유효 데이터면 DMA 시작 가능하다.
-
DMA->디스크 컨트롤러: Requests transfer to Mem -
디스크 컨트롤러->디스크: Data transferred -
디스크 컨트롤러->DMA: ACK (쓰기 완료 후 응답) -
DMA->CPU: interrupt
인터럽트 처리에 의한 I/O
- 입출력 인터페이스가 I/O 장치의 상태를 검사해 준비되면
인터럽트신호를 발생해 입출력 처리를 요구한다. -
CPU는 context switching 을 통해 인터럽트 서비스 프로그램을 수행한다.
- 입출력이 처리될 때까지 CPU가 다른 작업을 수행할 수 있어 효율성이 증가된다.
인터럽트란?
-
입출력 제어기가 주변장치의 입출력 요구나 하드웨어 이상 현상을 CPU에 알려주는 역할을 하는 신호
-
CPU가 요청 한 작업을 완료했을 때,
- 키보드로 데이터를 입력받았을 때,
- 네트워크 카드에 새로운 데이터가 도착했을 때,
- 하드웨어에 이상이 생겼을 때.
-
-
각 장치에는 IRQ라는 고유의 인터럽트 번호를 부여해 CPU는 어떤 장치에서 발생한 인터럽트인지 파악한다.
-
외부 인터럽트: 입출력 및 하드웨어 관련 인터럽트(ex. 전원 이상, 기계적 오류)
-
내부 인터럽트: 프로세스의 오류로 발생하는 인터럽트(ex. 숫자 0으로 나누기, 주소공간 벗어나는 작업하기)
-
시그널: 사용자의 요청으로 발생하는 인터럽트(ex. 리눅스에서 ctrl + c로 작동중인 프로세스 끝내기)
프로그램에 의한 I/O
- CPU 상에서 실행되는
프로그램에 의해 입출력이 제어 됨 - CPU는 I/O 장치에 명령을 보내고 동작이 완료될 때까지 대기한다.
- CPU는 주기적으로 I/O 장치의 상태를 검사해야 한다. (폴링 방식)
- CPU 자원이 낭비된다.
디스크 관리
- 컴퓨터의 대표적인 2차 저장장치
- 메모리는 휘발성이라 전원이 나가면 내용이 사라지지만, 디스크는 소멸하지 않는 기억장치다. (영속성)
-
프로그램 실행을 위한 메모리의 부족으로 인해 사용 (Swap space)
- 하드디스크 : 움직이는 헤드를 가진 하드디스크 드라이브
하드 디스크 구조
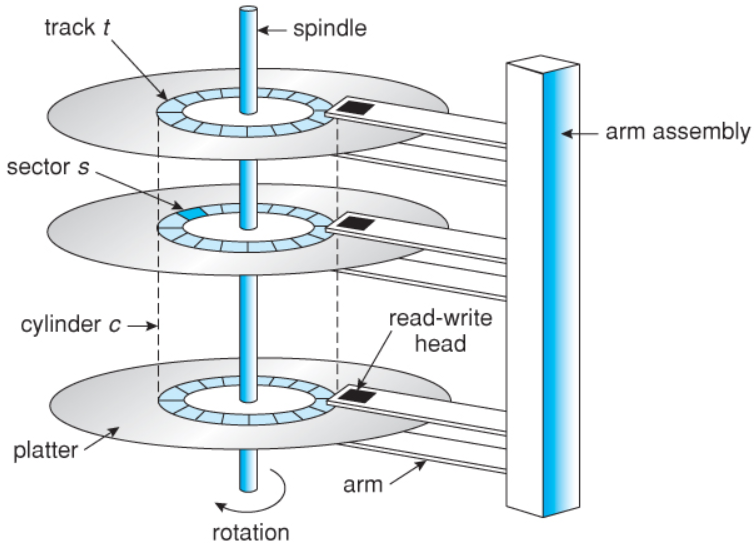
하드디스크는 스핀들(spindle)이라는 원통 축에 여러 개의 플래터(platter)가 달려있는 구조이다.
- 플래터 : 표면에 자성체가 발려 있어 자기를 이용하여 0과 1의 데이터를 저장. 항상 일정한 속도로 회전함. (일반적으로 일반 컴퓨터에는 3.5인치를 노트북에는 2.5인치를 사용)
- 트랙: 플래터에서 회전축을 중심으로 데이터가 기록되는 동심원(섹터의 집합)
-
섹터: 물리적 개념. 하드디스크의 가장 적은 저장 단위.
- 실린더: 여러 개의 플래터에 있는 같은 트랙의 집합
- 헤드: 데이터를 읽거나 쓸 때 사용하는 부위
여기서 잠깐!
디스크의 내부, 물리적으로는 Sector 가 가장 작은 단위지만,
디스크의 외부, 논리적으로는 Block 이 가장 작은 단위로 사용된다.
디스크의 데이터 전송 시간
- 각속도 일정 방식의 회전 : 일정한 시간 동안 이동한 각도가 같다.
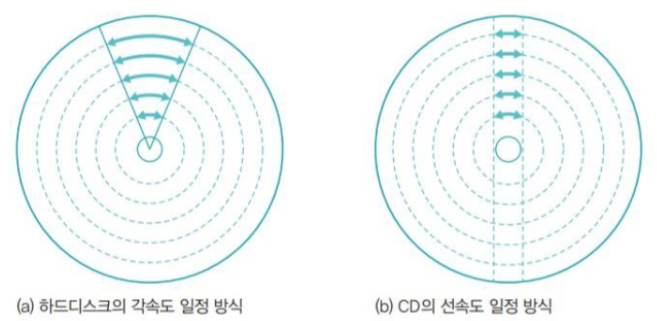
하드디스크의 플래터는 항상 일정한 속도로 회전하여 바깥쪽 트랙의 속도가 안쪽 트랙의 속도보다 훨씬 빠르다.
- 데이터 전송 시간 = 탐색 시간 + 회전 지연 시간 + 전송 시간
![]()
- 탐색 시간: 헤드가 특정 섹터의 트랙까지 이동하는데 걸리는 시간
- 회전 지연 시간: 플래터가 회전하여 원하는 섹터를 만날 때 까지 걸리는 시간
- 전송 시간: 헤드가 섹터에 있는 데이터를 읽어 전송하는 시간
Disk Management
- 하나의 물리적 디스크를 논리적 디스크로 파티셔닝 한 후,
- Disk에 파일 시스템을 설치해 사용하거나, Swap area 로 사용할 수 있다.
Physical Formatting (Low-level)
- 디스크 컨트롤러가 읽고 쓸 수 있도록 섹터를 나누는 과정
- 각 섹터는 Header + 실제 Data (보통 512 byte) + Trailer 로 구성된다.
- Header 와 Trailer는 컨트롤러가 직접 접근해 운영한다.
Partitioning
- 디스크를 하나 이상의 실린더 그룹으로 나누는 과정
- OS는 이것을 독립적인 disk 로 취급한다. (Logical Disk)
Logical Formatting
- 파일 시스템 만들기
- FAT, I-node 등의 구조를 포함한다.
Booting
- ROM 에 있는 “small bootstrap loader”의 실행
- Sector 0 은 모든 디스크에서 Boot block 이다.
디스크 스케줄링
- 디스크의 데이터 전송 시간 중에는 탐색 시간이 가장 느리다.
- 디스크 스케줄링(disk scheduling)은 트랙의 이동을 최소화하여 이 탐색 시간을 줄이는데 목적이 있다.
- 일반적으로 디스크 스케줄러가 실제 디스크 안에 존재하는 것은 아니므로, 논리 블럭 단위로 스케줄링 한다.
- 디스크 스케줄링 알고리즘은 교체할 수 있도록 OS와 별도의 모듈로 작성되는 것이 바람직하다.

디스크 스케줄링 종류
FCFS 디스크 스케줄링
-
가장 단순한 디스크 스케줄링 방식으로, 요청이 들어온 트랙 순서대로 서비스
-
15 -> 8 -> 17 -> 11 -> 3 -> 23 -> 19 -> 14 -> 20 (이동 거리 65)
SSTF(Shortest Seek Time First) 디스크 스케줄링
- 현재 헤드가 있는 위치에서 가장 가까운 트랙부터 서비스
-
만약 다음에 서비스할 두 트랙의 거리가 같다면 먼저 요청받는 트랙을 서비스
- 15 -> 14 -> 17 -> 19 -> 20 -> 23 -> 11 -> 8 -> 5 (이동 거리 31)
- 효율성은 좋지만 아사 현상을 일으킬 수 있음. 헤드가 중간에 위치하면 가장 안쪽이나 바깥쪽에 갈 확률이 적어짐
블록 SSTF 스케줄링
- 블록 단위로 트랙을 관리하여 멀리 있는 트랙도 몇 번만 양보하면 서비스 받을 수 있음(에이징 적용)
-
공평성 위배를 어느 정도 해결한 방법
- 15 -> 17 -> 8 -> 11 -> 3 -> 23 -> 20 -> 19 -> 15 (이동 거리 51)
- FCFS 보다 성능이 좋지 않음
SCAN 디스크 스케줄링
- disk arm이 디스크 한 쪽 끝에서 다른 쪽 끝으로 이동하며 가는 길목에 있는 모든 요청을 처리하는 방식
-
가장 많이 사용되는 기법 중 하나
- 15 -> 14 -> 11 -> 8 -> 3 -> 0 -> 17 -> 19 -> 20 -> 23 (이동 거리 38)
- 디스크 헤드 이동거리 측면에서 효율적이다.
- SSTF 보다 성능이 조금 떨어지지만 FCFS 보다 성능이 좋음
- 실린더 위치에 따라 대기 시간이 다르다는 문제점
- 동일한 트랙의 요청이 연속적으로 발생되면 헤드가 더 이상 나아가지 못해 바깥쪽 트랙이 아사 현상을 겪는 문제 발생
C-SCAN 디스크 스케줄링
- 헤드가 한 쪽 끝에서 다른 쪽 끝으로 이동하며 길목에 있는 모든 요청을 처리
-
다른 쪽 끝에 도달하면 요청을 처리하지 않고 바로 출발점으로 이동한다.
- 15 -> 14 -> 11 -> 8 -> 3 -> 0 -> (작업없이 이동) -> 24 -> 23 -> 20 -> 19 -> 17 (이동 거리 46)
- SCAN 보다 균일한 대기 시간을 제공함
- 그러나 작업 없이 헤드를 이동하여 매우 비효율적
LOOK 디스크 스케줄링
-
더 이상 서비스할 트랙이 없으면 헤드가 끝가지 가지 않고 중간에서 방향을 바꿈
-
15 -> 14 -> 11 -> 8 -> 3 -> 17 -> 19 -> 20 -> 23 (이동 거리 35)
C-LOOK 디스크 스케줄링
-
C-SCAN의 LOOK 버전
-
15 -> 14 -> 11 -> 8 -> 3 -> (작업없이 이동) -> 23 -> 20 -> 19 -> 17(이동 거리 38)
RAID(Redundant Array of Inexpensive/Independent Disk)
-
디스크 여러 개를 묶어서 사용
-
RAID는 자동으로 백업을 하고 장애 발생 시 이를 복구하는 시스템이다.
-
RAID 0, 1, 10, 2, 3, 4, 5, 6, 50, 60 등이 있음. (중복 저장 정도를 어떻게 하느냐)
RAID 종류
RAID 0(스트라이핑)
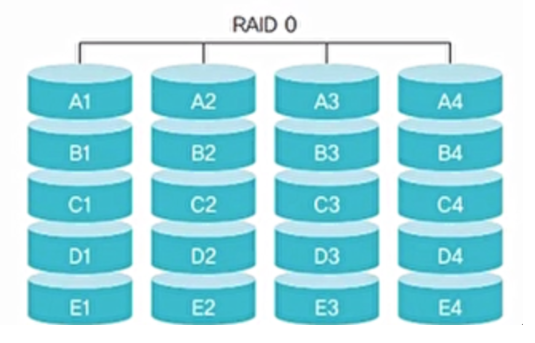
- 같은 규격의 디스크를 병렬로 연결하여 여러 개의 데이터를 여러 디스크에 동시에 저장하거나 가져올 수 있음
- 데이터를 여러 갈래로 찢어서 저장하기 때문에 스트라이핑이라고 부름
- N개의 디스크로 구성된 RAID 0은 1개의 디스크로 구성된 시스템보다 약 N배 빠름
- 장애 발생 시 복구하는 기능이 없음
- 따라서 속도는 증가하지만 안정성은 낮아짐
RAID 1(미러링)
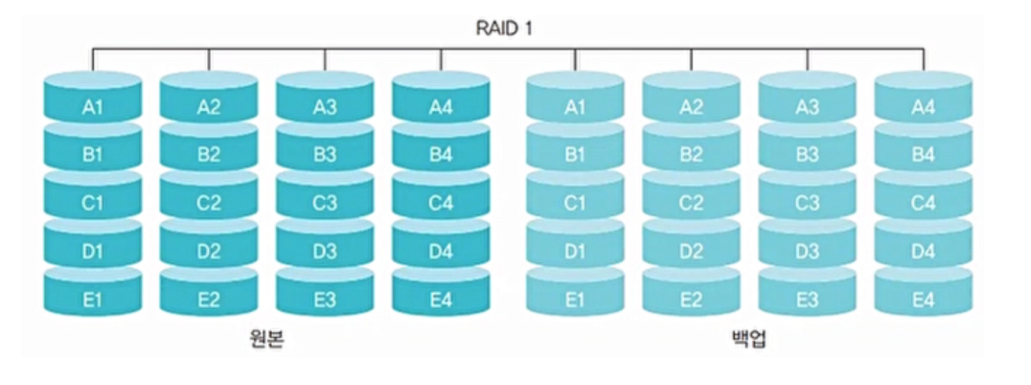
- 같은 데이터를 2개의 디스크에 저장(백업 디스크 활용)
- 같은 크기의 데이터를 최소 2개 이상 필요로 하며 짝수 개의 디스크로 구성
- 장애 발생시 미러링된 디스크를 활용하여 데이터를 복구할 수 있음
- 그러나 비용이 증가하고 같은 내용을 두 번 저장하기 때문에 속도가 느려짐
RAID 2
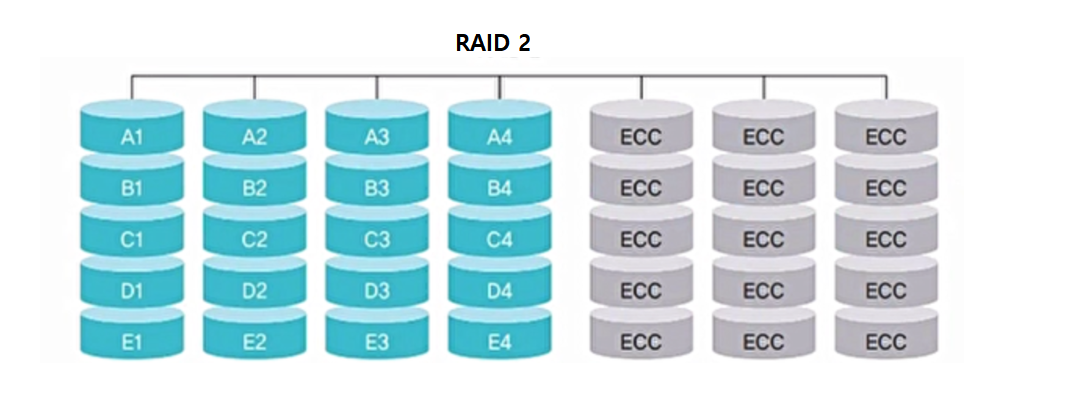
- 오류 교정 코드(ECC)를 따로 관리하여 오류가 발생하면 디스크를 복구
- 비트별로 만들어진 오류 교정 코드는 별도의 디스크에 따로 보관하고 있다가 장애 발생시 이 코드를 이용
- n개의 디스크에 대해 오류 교정 코드를 저장하기 위한 n-1개의 추가 디스크 필요
- 오류 교정 코드를 계산하는데 시간을 소비
- 잘 사용되지 않음
RAID 3
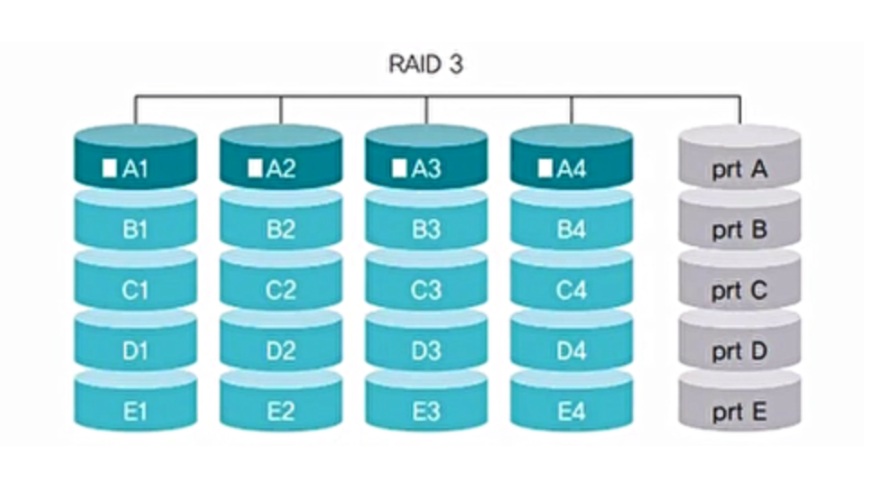
- 오류 검출 코드인 패리티를 사용하여 데이터를 복구.
- 섹터 단위로 데이터를 나누어 저장 짝수 패리티(1의 총수를 짝수로) 혹은 홀수 패리티(1의 총수를 홀수로)를 사용하여 장애가 난 비트를 추정
- 4개의 디스크당 1개 정도의 추가 디스크 필요
- 패리티 비트를 구성하는 데 많은 시간이 소비(데이터를 읽거나 쓸 때 패리티 비트를 구성하기 위해 모든 디스크가 동시에 동작해야 함)
RAID 4
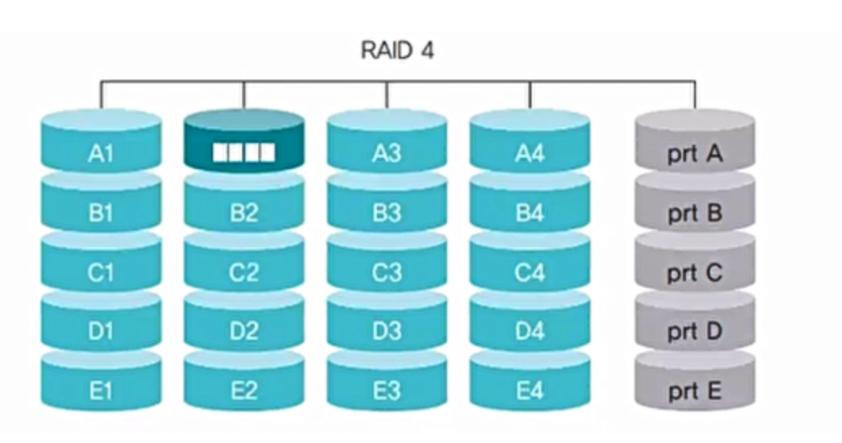
- RAID 3와 같은 방식이지만 블록 단위로 데이터를 나누어 저장
- 데이터가 저장되는 디스크와 패리티 비트가 저장되는 디스크만 동작한다는 것이 장점
- 패리티 비트를 추가하기 위한 계산량 많음. 그러나 추가되는 디스크 양 적음.
RAID 5
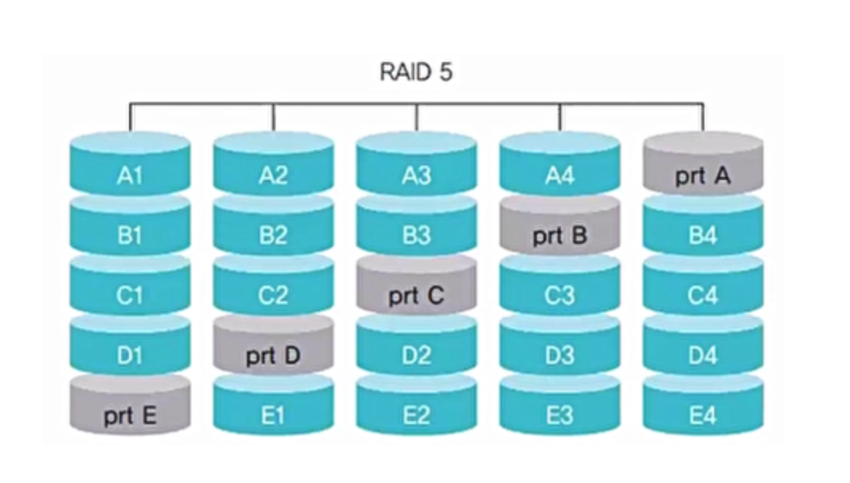
- 패리티비트를 여러 디스크에 분산하여 구성
- 병목 현상 완화
- 패리티 비트가 있는 디스크가 고장나도 복구 가능. 한 디스크에 장애 발생 시 다른 디스크에 있는 패리티 비트 이용해 복구
RAID 6
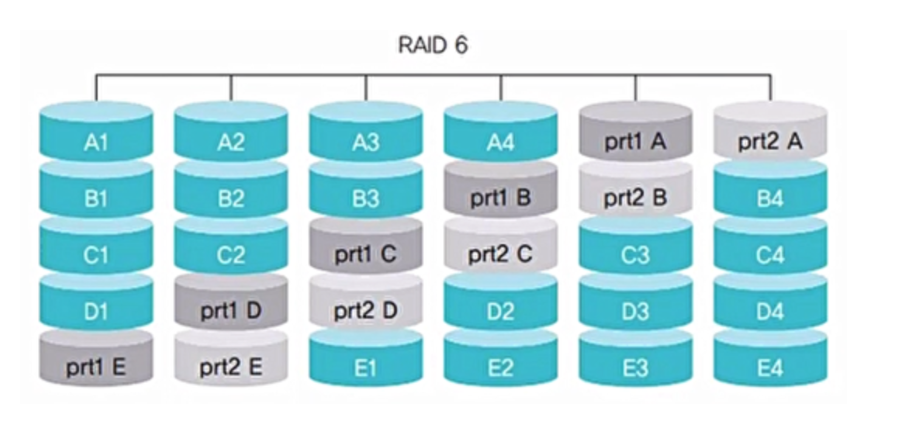
- RAID 5와 같은 방식이지만 패리티 비트가 2개
- RAID 5와 달리 디스크 2개가 동시에 장애가 발생했을 때도 복구 가능
- 패리티 비트를 2개씩 운영해서 부담이 커짐
RAID 10
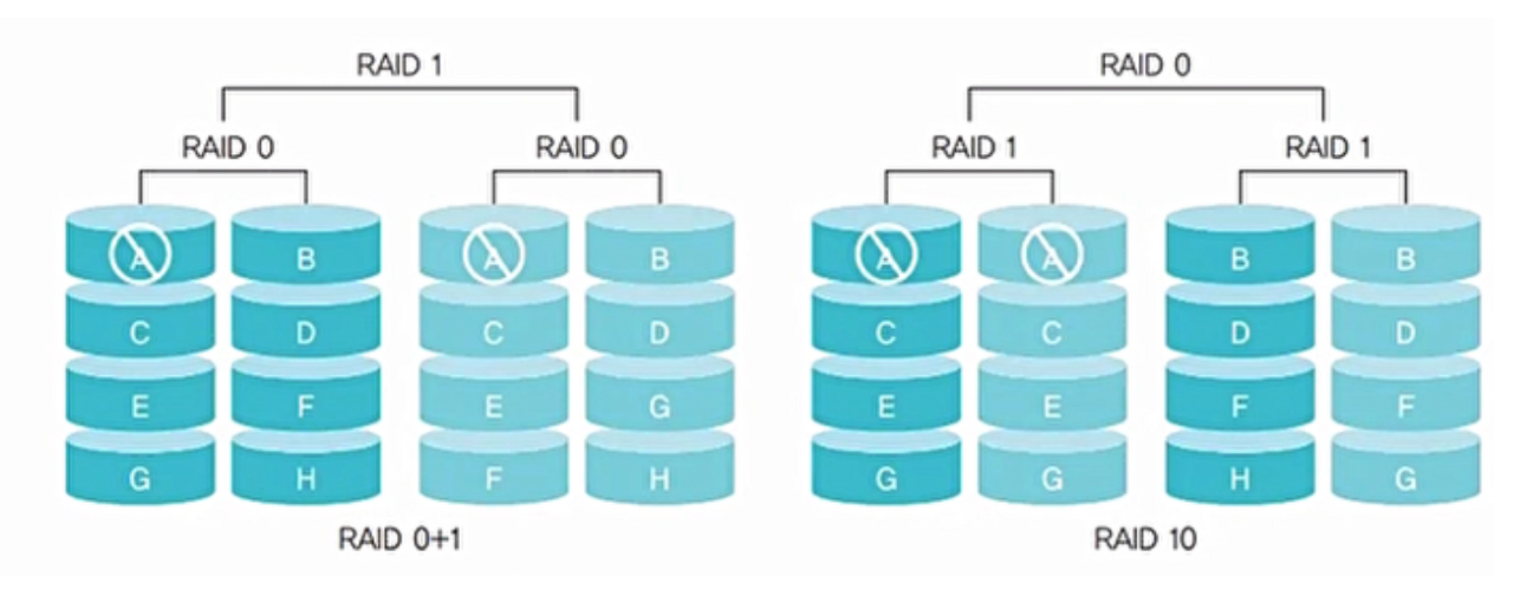
- 미러링 기능을 가진 RAID 1과 빠른 데이터 전송이 가능한 RAID 0을 결합한 형태
- RAID 01과 달리 일부 디스크만 중단하여 복구 가능
RAID 50 or 60
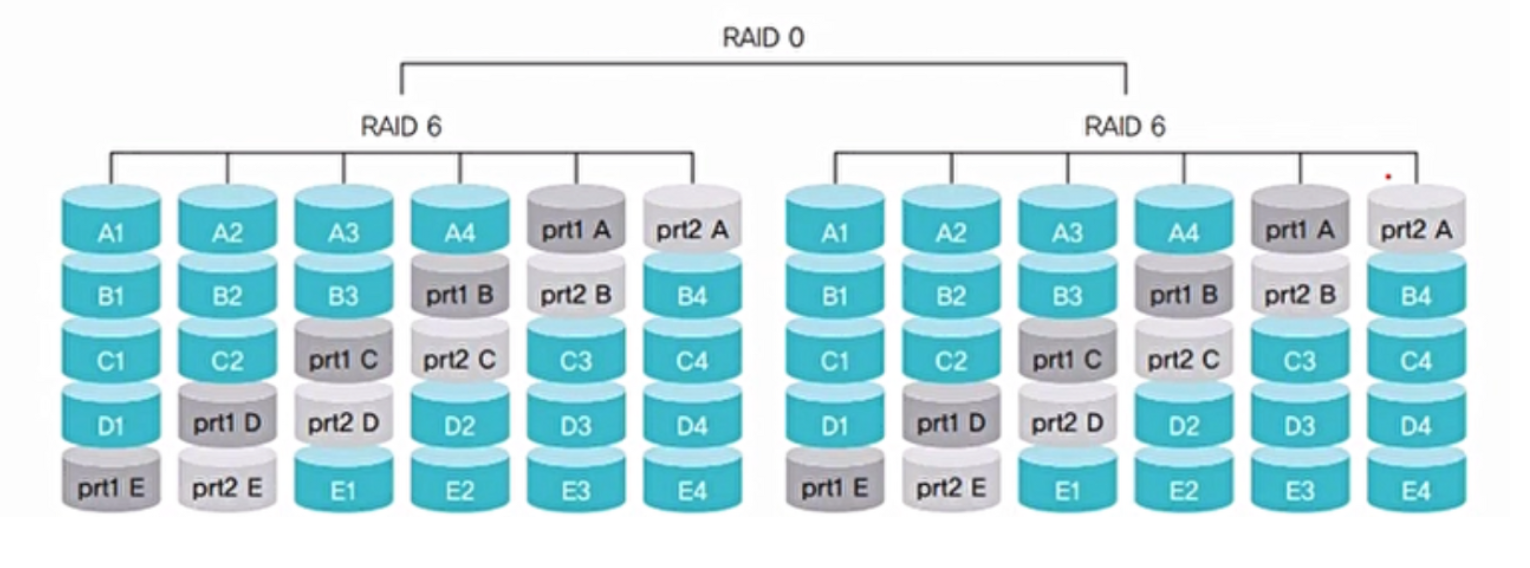
- RAID 5 또는 6으로 묶은 두 쌍을 다시 RAID 0으로 묶어 사용
사용 목적
- 처리 속도 향상 : 여러 디스크에 분산 저장하고, 병렬적으로 읽어온다. (Interleaving, striping)
- 신뢰성 향상 : 동일 정보를 여러 디스크에 중복 저장해 하나의 디스크가 고장나도 다른 디스크에서 읽어올 수 있다. (Mirroring, shadowing)
Reference
-
https://core.ewha.ac.kr/publicview/C0101020140311132925816476?vmode=f
-
http://itnovice1.blogspot.com/2019/09/dmadirect-memory-access.html